分布式ID解决⽅案
1. UUID
UUID 是指Universally Unique Identifier,翻译为中⽂是通⽤唯⼀识别码
String uuid = UUID.randomUUID().toString().toString();
System.out.println(uuid); // 8d70a613-e9da-494d-a487-558c94c14366
2. 独⽴数据库的⾃增ID
单独的创建⼀个Mysql数据库,在这个数据库中创建⼀张表,这张表的ID设置为⾃增,其他地⽅需要全局唯⼀ID的时候,就模拟向这个Mysql数据库的这张表中模拟插⼊⼀条记录,此时ID会⾃增,然后我们可以通过Mysql的select last_insert_id() 获取到刚刚这张表中⾃增⽣成的ID
-- ----------------------------
-- Table structure for DISTRIBUTE_ID
-- ----------------------------
DROP TABLE IF EXISTS `DISTRIBUTE_ID`;
CREATE TABLE `DISTRIBUTE_ID` (
`id` bigint(32) NOT NULL AUTO_INCREMENT COMMENT '主键',
`createtime` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
哪个应⽤需要获取⼀个全局唯⼀的分布式ID的时候,就可以使⽤代码连接这个数据库实例,执⾏insert操作,使用LAST_INSERT_ID()获取新生成的ID
注意
- 这⾥的createtime字段⽆实际意义,是为了随便插⼊⼀条数据以⾄于能够⾃增id
- 使⽤独⽴的Mysql实例⽣成分布式id,虽然可⾏,但是性能和可靠性都不够好,因为你需要代码连接到数据库才能获取到id,性能⽆法保障,另外mysql数据库实例挂掉了,那么就⽆法获取分布式id了。
- 有⼀些开发者⼜针对上述的情况将⽤于⽣成分布式id的mysql数据库设计成了⼀个集群架构,那么其实这种⽅式现在基本不⽤,因为过于麻烦了。
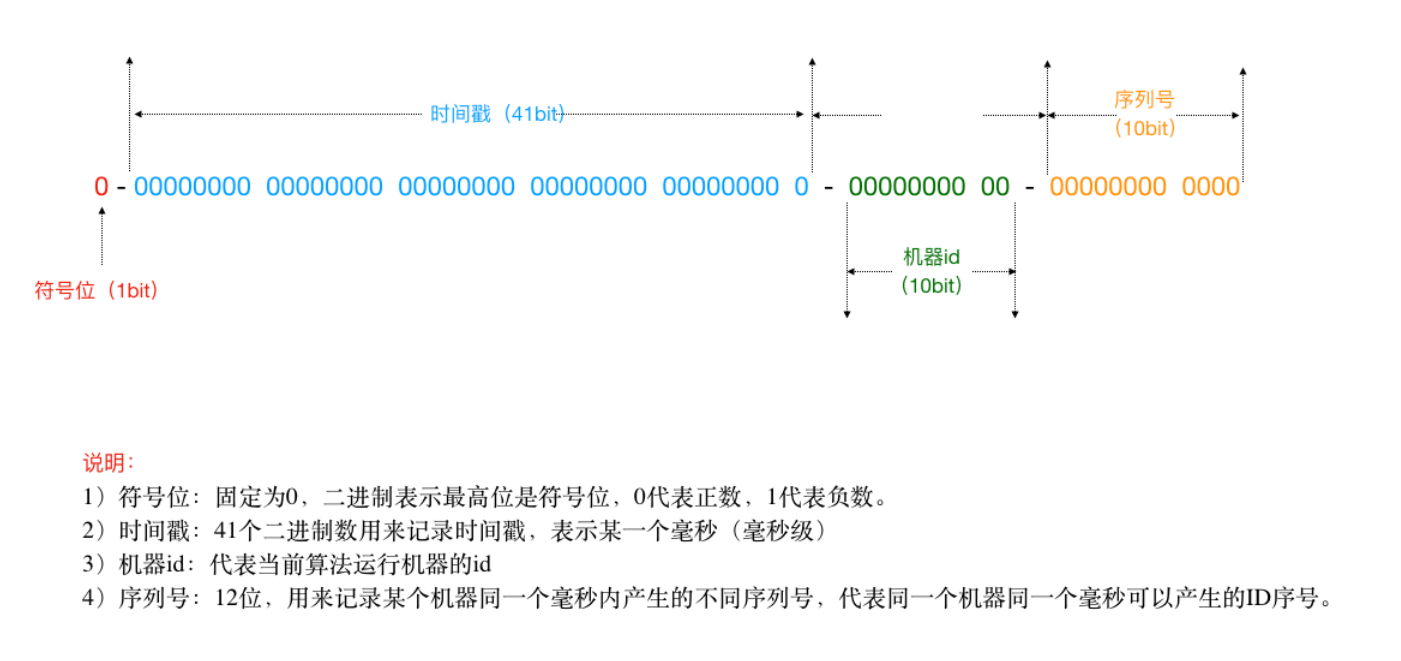
3. SnowFlake 雪花算法
雪花算法是Twitter推出的⼀个⽤于⽣成分布式ID的算法。基于这个算法可以⽣成ID,⽣成的ID是⼀个long型,那么在Java中⼀个long型是8个字节,算下来是64bit,如下是使⽤雪花算法⽣成的⼀个ID的⼆进制形式示意:
/**
* twitter的snowflake算法 -- java实现
*/
public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5;//数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(2, 3);
for (int i = 0; i < (1 << 12); i++) {
System.out.println(snowFlake.nextId());
}
}
}
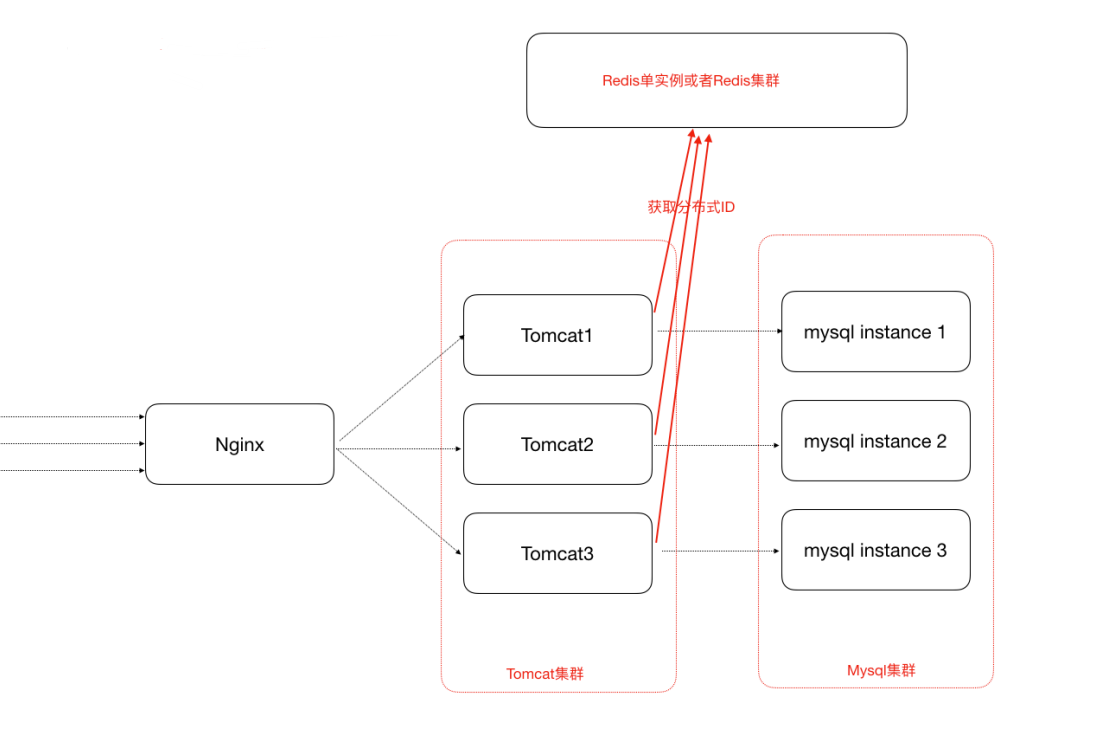
4. 借助Redis的Incr命令获取全局唯⼀ID
Redis Incr 命令将 key 中储存的数字值增⼀。如果 key 不存在,那么 key 的值会先被初始化为 0,然后再执⾏ INCR 操作。
Jedis jedis = new Jedis("127.0.0.1",6379);
try {
long id = jedis.incr("id");
System.out.println("从redis中获取的分布式id为:" + id);
} finally {
if (null != jedis) {
jedis.close();
} }